週末、お世話になっているお店でのおいしい食事をいただきました。

刺身から始まり。この切付の時点で鮮度と腕がうかがえます。

蒸したジャガバターの上にウニをのせるという背徳的な食べ方をしたり

旬のホタルイカの酢味噌和え、

店の自作という牡蠣のオイル漬け。
この時点でも感動は極上でしたが、まだ続きがあります。


週末、お世話になっているお店でのおいしい食事をいただきました。
刺身から始まり。この切付の時点で鮮度と腕がうかがえます。
蒸したジャガバターの上にウニをのせるという背徳的な食べ方をしたり
旬のホタルイカの酢味噌和え、
店の自作という牡蠣のオイル漬け。
この時点でも感動は極上でしたが、まだ続きがあります。

友人と卓を囲みました。

色を絞れたこともあり、40点差をつけての勝利。(上のタイルは計算のため順番を変えています)

納涼落語会での『牡丹灯籠』に年末落語会の『芝浜』をかけることができました。

一色10点で勝利。発展カードの偏りを読み取れたのが功を奏しました。
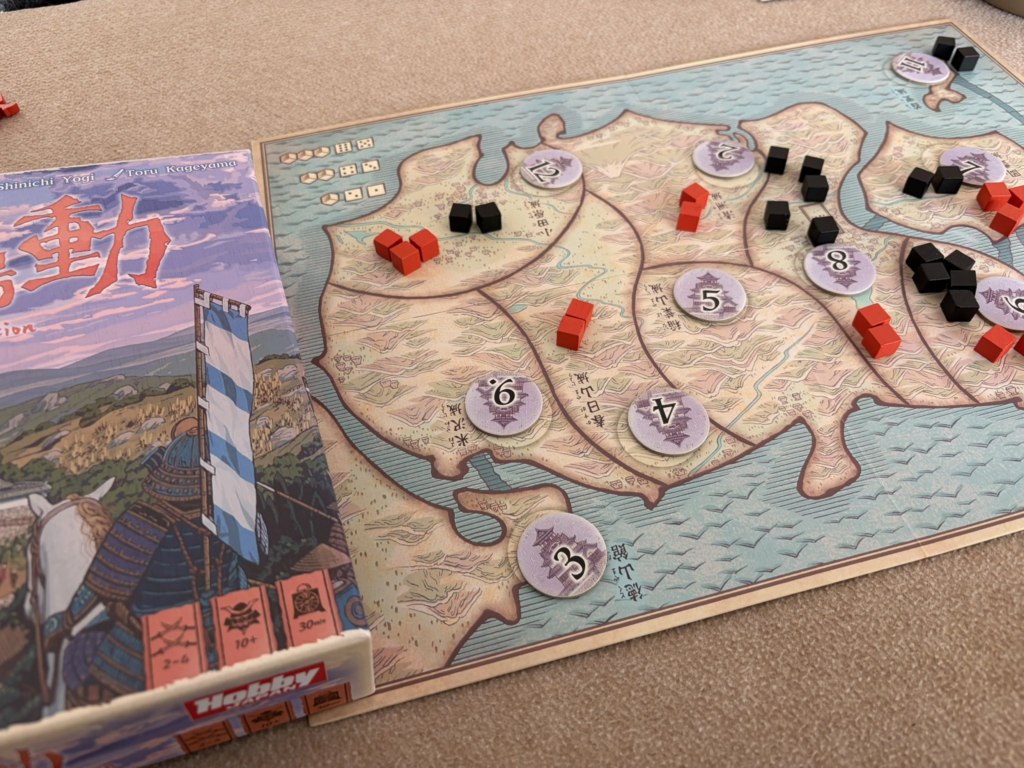
計略カードと援軍が勝敗を形づけるゲーム。運と戦略が絡むゲームではありましたが敗北。
いい気分転換でした。

警告: 実行中のバージョン: 2.0.4~docker; サーバーはこのTalkバージョンの全ての機能をサポートしていません。欠落している機能: chat-relay
と出たので、それに対応していきます。
アップデートは、こちらの手順で、コマンドラインから行いました。
その後、管理画面で上記のエラーが出たという次第です。
このNextcloudを個人的に運用しているのならばそのまま行って構いません。しかし、これを組織で運用しているとなると話はまるで違います。
※ 検証環境を用意できる程度には時間と予算と環境に余裕がある方は、その環境にいることを感謝しつつ、検証を重ねていきましょう。
cd /path/to/nextcloud/root/directory && pwd自分の環境に合わせます。(筆者環境/home/www-data/nextcloud)
sudo -u www-data php occ maintenance:mode --on運用中のNextcloudのURLにアクセスし、メンテナンスモードであることを確認します。
server.conf) の構成sudo cp -pi /hoge/docker/files/nextcloud-signaling/server.conf /path/to/backup/directory/server.conf.$(date +%Y%m%d)自分の環境に合わせます。
diff -u /path/to/backup/directory/server.conf.$(date +%Y%m%d) /hoge/docker/files/nextcloud-signaling/server.conf差分がないことを確認します。
server.confファイル修正chat-relay 機能を有効にするため、以下のように項目を付け加えます。
[chat]
enabled = true追記したら保存を行います。
diff -u /path/to/backup/directory/server.conf.$(date +%Y%m%d) /hoge/docker/files/nextcloud-signaling/server.conf以下の差分を確認します。
+ [chat]
+ enabled = trueこれが地味にハマりました。古い docker-compose (v1.29.x等) を使用している環境だと、イメージのメタデータ構造の違いによるエラー(KeyError: 'ContainerConfig')が発生。
それを避けるための手順です。
docker-compose を介さず、Docker本体で最新イメージをプルする。
sudo docker pull strukturag/nextcloud-spreed-signaling:latestsudo docker pull nats:2.9作成失敗などで残った残骸を削除し、競合を防ぐ。
sudo docker container prune -fsudo docker-compose up -dsudo -u www-data php occ maintenance:mode --off運用中のNextcloudのURLにアクセスし、管理画面に入ります。
Nextcloudの「設定」>「Talk」にある高性能バックエンド設定で、URL横の「チェックマーク(保存)」を押し、chat-relay が Available features に含まれたことを確認して対処完了です。
Dockerは確かに便利な代物ですが、管理が複雑になっていくというのが難点。それ故、Dockerは最小限にして登録していきたいものです。

宅内でのサーバとして立てているUbuntu20.04という完全にEOLを迎えている機体。それがエラーを起こしたときのメモです。
Ubuntu 20.04を入れているミニPCの起動時、画面に以下のメッセージが表示され、デスクトップが立ち上がらずに (initramfs) というプロンプトで停止しました。
sgx: disabled by BIOS(initramfs) _ (入力待ち状態)以下、Geminiからのアドバイス。
これに従って対処を行いました。
(initramfs) プロンプトで exit を入力
エラーの詳細(どのパーティションが壊れているか)を確認するために、まず exit と打ちます。
The root filesystem on /dev/sdb2 requires a manual fsck
というメッセージが表示されました(筆者環境)これをメモします。
特定したデバイス名に対して修復コマンドを実行します。
fsck /dev/sdb2 -y※ -y オプションを付けることで、すべての修復箇所を自動で「Yes」として処理します。
FILE SYSTEM WAS MODIFIED と表示されたら、以下のコマンドで再起動(またはブート続行)を試みます。
rebootまたは
exit機器が古すぎたためのディスクエラー につきます。
これが仕事でしたら「さっさと取り替えろ」「いや、取り替えないように準備する」なのですが、自分の環境なのでそうはいかず。
なんとか予算と時間を見つけてリプレースをする必要に迫られました。

こちらのデッキで用いるトークン群をGemini nano banana 2にて生成。

それに合わせて、
統率者でよく混乱しがちになる

などを生成した後、L判で出力。B7ハードケースにも詰めました。

隙間があるのが課題なので、そのあたりを詰めればもっといいものになりそうです。

行き狩りの電車でプレイしている『ガイアプロジェクト』で珍しい事象が起きました。
使った勢力はお気に入りのダー・シュワーム。
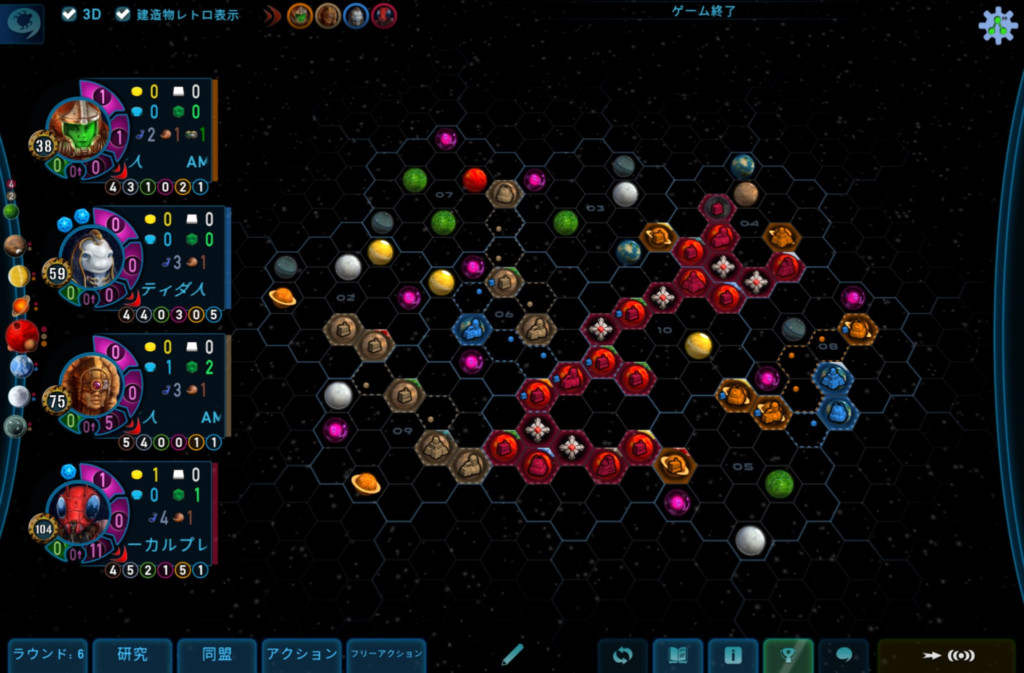
まず完成図がこちら。ここまで宙域を伸ばしているのも異例ですが
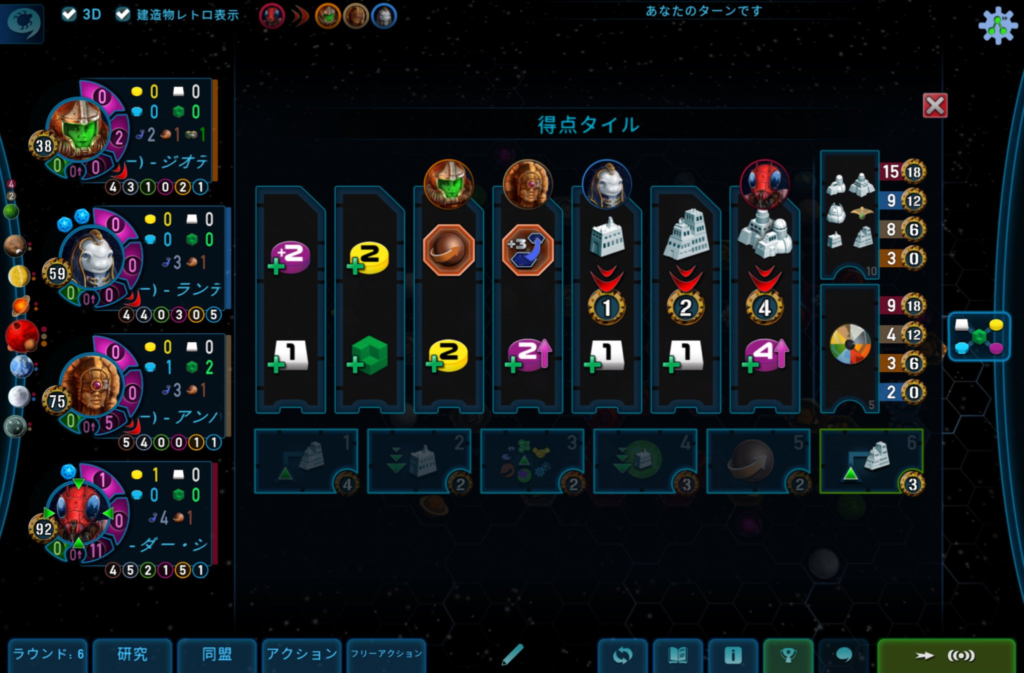
マジョリティ「惑星改造」が9。つまり、航法5の暗黒惑星を含めてコンプリート。
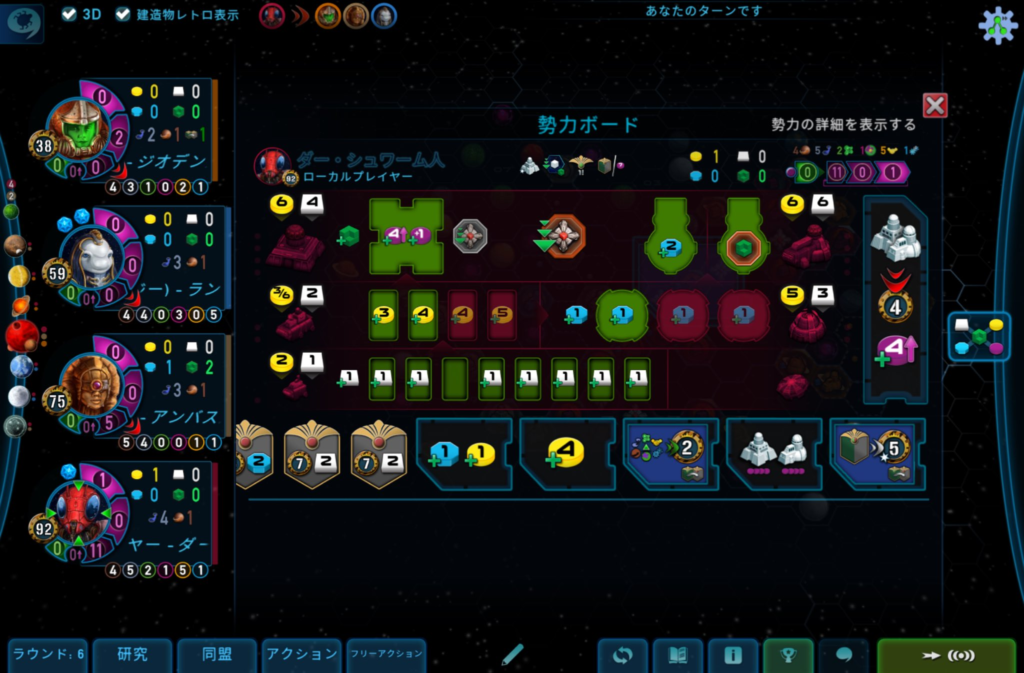
惑星改造ゴールはアンバスに取られたものの、同盟×5タイルと研究ごとに2点タイルを取ることができて
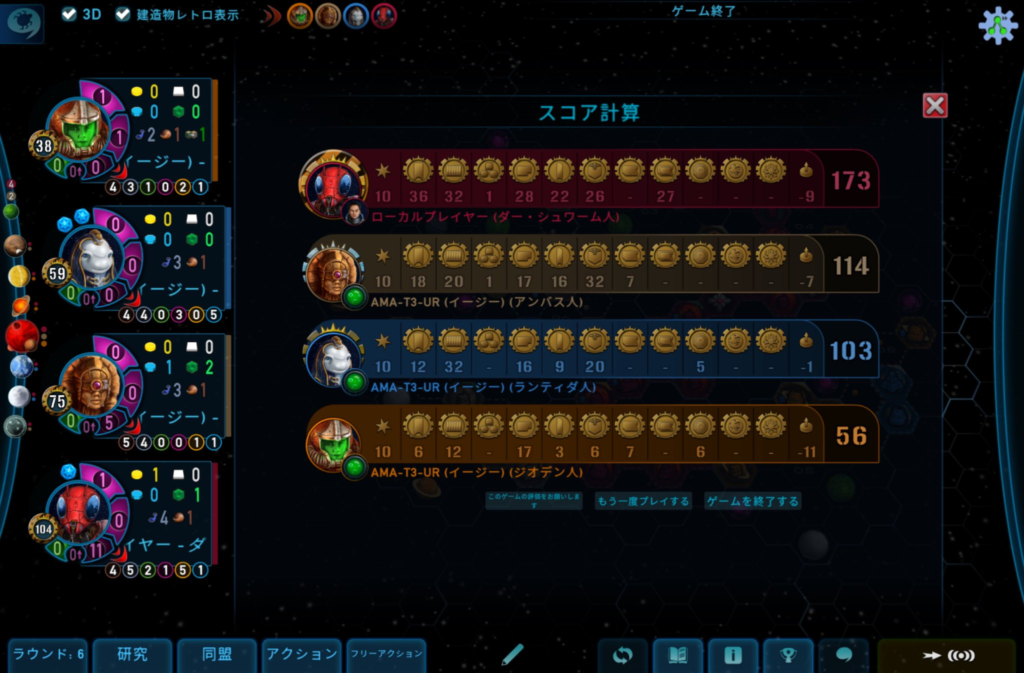
最終得点は173点。まず取ることがない航法ゴールをダー・シュワームでやったという珍事です。

何かと現役なUSBメモリ。再セットアップ中に(Windows管理→ディスク管理)

このように見割り当て/もしくは複数のパーティションができた場合に対応するときのメモです。
この操作を行うと、USBメモリ内のデータはすべて消去されます。 必要なファイルがある場合は、作業前に必ずパソコン本体などへバックアップを取ってください。
ディスク番号は絶対に間違えないでください。
OSインストールドライブが文字通り吹っ飛ぶような操作です。
Windowsキー→cmdを入力。コマンドプロンプトが入力されたら、右クリックで「管理者として実行」を選択。
diskpartを入力してEnterを実行。
list diskを実行。
この時、上述したディスク3が操作をするUSBメモリであることを確認しましょう。
※ここでディスク番号を間違えると、パソコンのSSDなどを消去してしまうため慎重に選んでください。
select disk 3を実行します。「ディスク 3 が選択されました」と表示されます。
cleanを実行します。これで、ディスク内の全てのパーティションが消えます。
create partition primaryを実行します。
fs=ntfs quick等でフォーマットを行います。
exitでdiskpartを抜けます。
1年前に買ったまま放置していたデッキをようやく組めました。
ネットで見た改造案を元に、進化とトークン戦略。ゲームチェンジャーを一切入れないブラケット2に抑えています。
あなたが工匠(Artificer)やアーティファクトである呪文1つを唱えるたび、(E)(エネルギー(energy)・カウンター1個)を得る。
あなたのターンの戦闘の開始時に、(E)(E)(E)を支払ってもよい。そうしたとき、あなたがコントロールしているパーマネント1つを対象とする。他のタイプに加えて速攻を持つ5/5のアーティファクト・クリーチャーであることを除き、それのコピーであるトークン1体を生成する。次の終了ステップの開始時に、そのトークンを生け贄に捧げる。
という統率者。高名な者、ミシュラと似たような挙動ですが
というのが微妙に違います。なので、
など、結構面白い動きができそうです。
最初に手にした統率者構築済みデッキを「ブラケット2」の帯にしました。
青赤緑
グレムリンの神童、ジンバル
トークンを並べてビートダウン
現行のデッキリスト
あなたがコントロールしているすべてのアーティファクト・クリーチャーはトランプルを持つ。
あなたの終了ステップの開始時に、赤の0/0のグレムリン(Gremlin)・アーティファクト・クリーチャー・トークン1体を生成する。それの上に+1/+1カウンターX個を置く。Xは、あなたがコントロールしていて名前の異なるアーティファクト・トークンの数に等しい。
これをずっと放置していたのは「トークン管理が面倒だったから」に尽きます。

全30種に及ぶトークンをようやく切り出すことができて

ゲームチェンジャーカードを抜いたものへと仕上げられました。

ポストアポカリプスな世界の中で、どのように時計を再生させていくかが問われるソリティアゲームでした。
人類が滅亡した世界。プレイヤーはロボットとして大時計をくみ上げていきます。
山札が尽きる前に大時計の再生が完了すればゲーム勝利となります。
最初に言いますが、本作は難易度高めです。ゲームのコツがつかめなければ、あっという間に山札が尽きてゲームに敗北します。
部品をくみ上げた際にもライブラリーが吹っ飛ぶような効果もあるので、「死にやすさ」を加速。それだけに、「次はどうすれば死なないか」の思考がフル回転しました。
途中で遭遇する災厄にしても地味にやっかいなものがあるし、3種類ある歯車にしても「次に同じカードは置けない」縛りがあるため、盤面と運を両方とも見ることが必要です。
反面、それを修復するための手段が「ここぞ」というタイミングで使うことができると盤面は一気に回復。その切り札的な手段を使って「生き延びた」時の安心感はひとしおです。
ゲームクリアに必要なのは部品なので、それを最優先したいところではありますが、生産拠点は手札の調整や災厄の軽減などの便利な効果を兼ね備えています。なので
「あちらがほしいが、次に引くかもしれない災厄にはこっちが必要」
というディシジョンメイキングに悩まされます。

この手の小箱にしては珍しくスリーブ付き。しかも、スリーブを入れるとしっかりと箱に収まるという心憎い配慮。
同梱のスリーブはジャストサイズです。なので、TCGに慣れていない方にとってこのスリーブ入れはかなり苦労するでしょう。
カードの偏りによっては山札の修復もできずに何もできません。このランダム性はかなりやっかいです。
山札を大幅に削る部品を序盤に発動しないと詰みます。これに気づくか気づかないかがこのゲームをどう思うかに直結です。
難解なゲームではありましたが、
など、訴求力はバッチリ。何より、15分程度で考えどころ満載の小箱ゲームでした。
個人的に:生産拠点が停止してしまう(裏返ってしまう)災厄を逆手に取り、山札の修復を使い回すテクニックは、TCGプレイヤー冥利に尽きました。
Powered by WordPress & Theme by Anders Norén