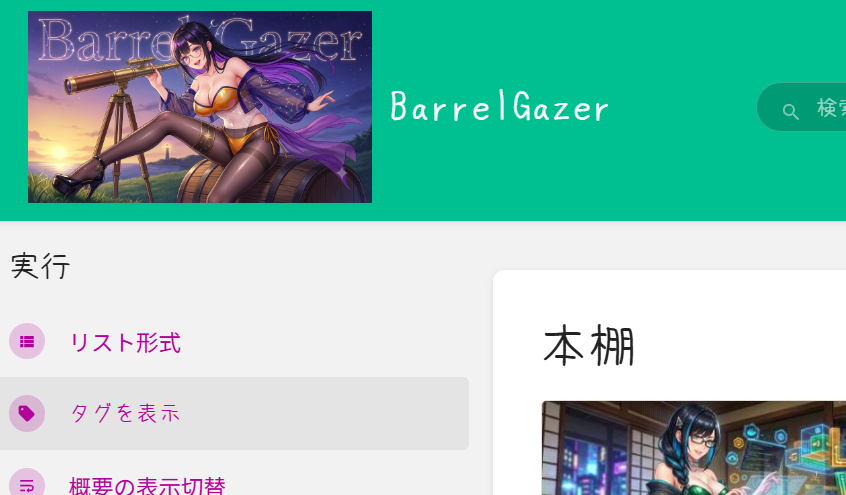
BookStackでは「アプリケーションロゴ」を設定できますが、そのままではアップロードした画像が高さ86pxへリサイズされてしまいます。
そのため、CSSでロゴを大きく表示すると画像がぼやけてしまいます。そもそも86pxは昨今のモダンなCMSにあるまじき解像度ではあるので、手を入れます。
そこでファイル本体を少し修正し、高解像度のロゴ画像をそのまま利用できるようにしました。
環境
- BookStack
- Apache
- PHP
- Ubuntu
最初に試したこと
BookStackに管理者権限でログインし、管理>カスタマイズに遷移。
カスタムheadタグで
<style>
.logo-image {
height: 128px !important;
width: auto !important;
}
</style>
のような指定はできるものの、超ローレぞ加工され、表示がぼやけます。そこで、要素を調べると、保存された画像自体が86×86になっていました。
この原因を調べます。
調査
インストールされているUbuntuサーバで
cd /path/to/BookStack/directory && pwd
として(筆者環境/home/www-data/Bookstack)BookStackのホームディレクトリに移動。
file public/uploads/images/system/20xx-xx/xxxx.jpg
で、該当のファイルを調べます。
JPEG image data
86x86
つまり、CSSではなくアップロード時に画像が縮小されていました。
分かった原因
いかにCSSで指定してもだめな原因はプログラムそのものにあります。なので、その上流の「ファイルのアップロードを司るファイル」にメスを入れます。
それを司るファイルをチャットAIとともに調査。
BookStackのルートディレクトリからたどれる
app/Settings/AppSettingsStore.php
にそれがありました。
protected function updateAppLogo(Request $request): void
{
if ($request->hasFile('app_logo')) {
$logoFile = $request->file('app_logo');
$this->destroyExistingSettingImage('app-logo');
$image = $this->imageRepo->saveNew(
$logoFile,
'system',
0,
null,
86
);
setting()->put('app-logo', $image->url);
}
}
null,
86
が指定されているため、高さ86pxへリサイズされた画像が保存されます。
ここまで分かれば、後は修正開始です。
さっくりとした手順
- サーバ上で該当するファイルを修正します。
- 念のためサービスの再起動を行います。
- カスタムheadタグを修正します。
- 改めてファイルをアップロードします。
ファイルのバックアップ
cd /path/to/BookStack/directory && pwd
自分の環境に合わせます。(筆者環境/home/www-data/Bookstack)
sudo cp -pi app/Settings/AppSettingsStore.php /path/to/backup/AppSettingsStore.php.$(date +%Y%m%d)
※注意点※
- プログラム根幹をいじります。つまり、何かあったら直したやつの責任です。バックアップは確実に取ります。
- 更に、Gitなどでアップデートした場合、確実にこれはMasterから上書きされます。「ここを直す」というのは履歴管理を厳に行いましょう。
- 該当ファイルのバックアップ確認
diff -u /path/to/backup/AppSettingsStore.php.$(date +%Y%m%d) app/Settings/AppSettingsStore.php
任意のバックアップディレクトリを指定します。
エラーがないことを確認します。人間「バックアップはやってる」と思いながらもバイアスや手なりでスキップしがちです。この段階でそのミスやバイアスを潰します。
なぜdiffを使うのかは、ls -lで両ファイルを比べるより確実だからと言うのと、後述する修正確認でも使うからです。
該当ファイルの修正
app/Settings/AppSettingsStore.phpファイルを、リサイズを行わないよう変更します。(要管理者権限)
具体的には以下の差分になるように。
- $image = $this->imageRepo->saveNew($logoFile, 'system', 0, null, 86);
+ $image = $this->imageRepo->saveNew($logoFile, 'system', 0, null, null);
diff -u /path/to/backup/AppSettingsStore.php.$(date +%Y%m%d) app/Settings/AppSettingsStore.php
ここで、なぜdiffを逆にする意味が生まれます。逆にしないと直したところが-、元が+で表示されます。これは視覚的にも感覚的にもよろしくありません。「え? 正しい修正をしたのに消されるの?」となりがちです。
設定反映
sudo -u www-data php artisan optimize:clear
でキャッシュをクリアします。
(推奨)PHP/Apacheを再起動
PHP-FPMなら
sudo systemctl restart php8.3-fpm
Mod-PHP環境なら
sudo systemctl restart apache2
で、実行環境を再起動します。
改めてカスタムヘッダの調整
BookStackに管理者権限でログインし、管理>カスタマイズに遷移。
カスタムheadタグで
<style>
.logo-image {
height: 128px !important;
width: auto !important;
}
</style>
のように設定し、(或いは設定されていることを確認し)、保存をクリック。
要してあるロゴをアップロード
管理>カスタマイズ
から、ファイルをアップロードします。
BookStack標準ではヘッダー高さが少し窮屈なので、必要に応じてヘッダーも調整します。
例
header {
min-height: 72px;
}
.logo-image {
height: 64px !important;
}
設定反映確認
ここから先はBookStackに戻り、高解像度でロゴが表示されれば設定はOKです。