Jetpackの代わりとして運用しているWeb解析、Matomo。更新もあまり手間を必要とせず利用可能でした。
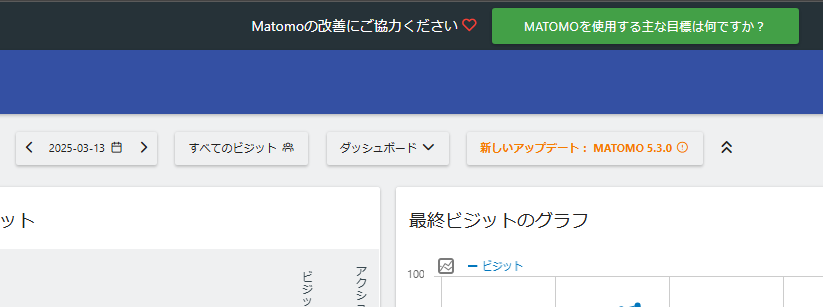
このように「新しいアップデート」ボタンが出てきますので
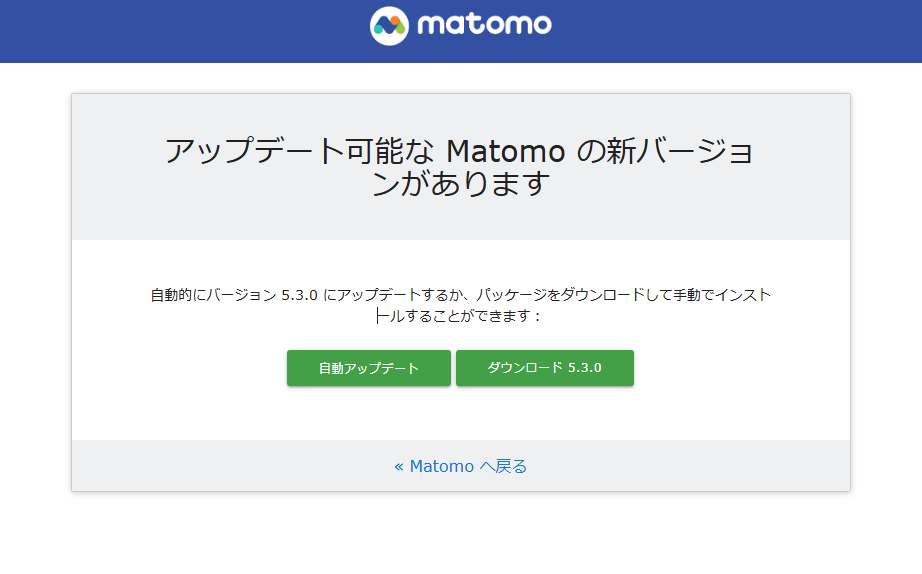
これを押した後に「自動アップデート」をクリック。
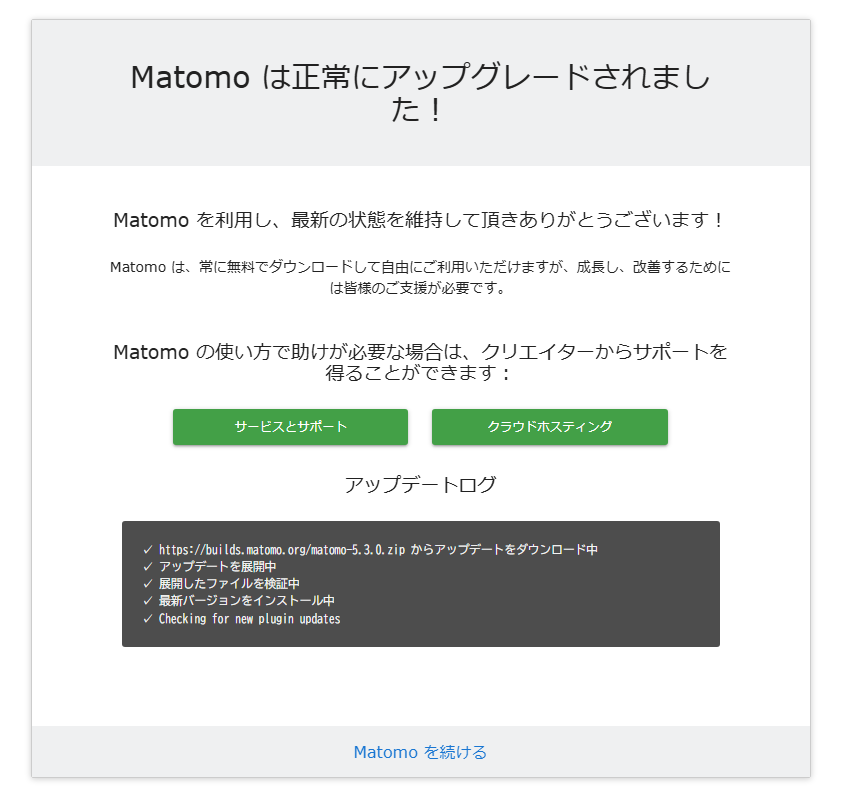
この成功の画面が出て、「Matomoを続ける」をクリック。
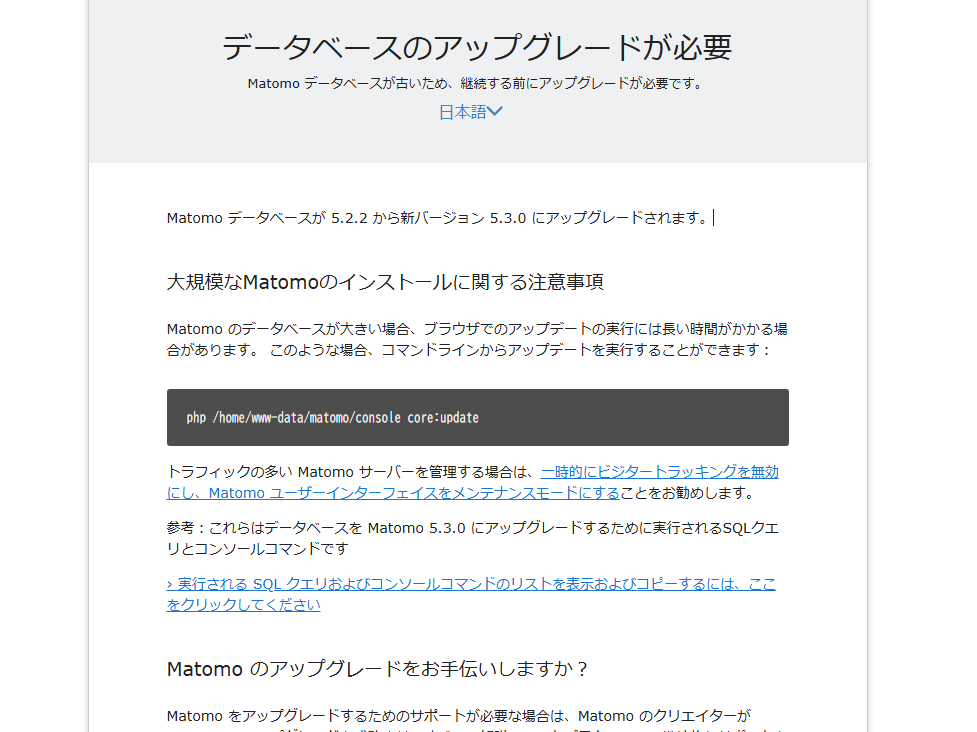
バージョンによってはDBのアップブレードを示唆されますので、
Matomoのアップグレードをクリック。
このDBのアップグレードも終われば完了。


Jetpackの代わりとして運用しているWeb解析、Matomo。更新もあまり手間を必要とせず利用可能でした。
このように「新しいアップデート」ボタンが出てきますので
これを押した後に「自動アップデート」をクリック。
この成功の画面が出て、「Matomoを続ける」をクリック。
バージョンによってはDBのアップブレードを示唆されますので、
Matomoのアップグレードをクリック。
このDBのアップグレードも終われば完了。

Growi v7.1.xをインストールしているのであれば、v7.2.0へのアップグレードはv7.1.xと同じ手順でアップグレードできました。
以下をバックアップします。
cat /etc/mongod.conf |grep dbPathとして、ここのディレクトリ一式を控えます。(筆者環境 /home/mongodb)
このディレクトリを任意の方法でバックアップします。
/growi/root/directory/apps/app/public(筆者環境 /home/www-data/growi/apps/app/public)ここも念のためバックアップします。
※ 添付ファイルのアップロード先をAWSやAzureなどにしている場合は不要です
スナップショット機能などでシステム全体をバックアップした方が確実で安心です。
systemctl status growi.service※ サービススクリプト名は自分の環境に合わせます。
※ active(running)を確認します
sudo systemctl stop growi.servicesystemctl status growi.serviceinactive (dead)を確認します
cd /opt/growi自分の環境に合わせます。(筆者環境/home/www-data/growi)
sudo git fetch --tagssudo git tag -lスペースで確認していき、上記リリースサイトと同じバージョンがあることを確認します。
sudo git stashsudo git checkout 【バージョン】sudo pnpm isudo npm run app:buildsystemctl status growi.serviceinactive (dead)を確認します
sudo systemctl start growi.service※ 完全に起動していないと、アクセスしても503エラーが発生します。
systemctl status growi.service→ サービススクリプトを[growi]にしている場合
active (running)を確認します
必要に応じてバックアップしたファイル一式やスナップショットを削除します。

企業内やコミュニティでNextcloudを運用する際のアカウント作成は割と簡単ですが、
{{thumbnail(clipboard-202503081731-br3pd.png, size=640)}}
このようにデフォルトのファイルがアカウントを作成するたびに増えていきます。
1アカウントにつき33MB程ではありますが、不要なファイルではあるので
ように修正します。
以下の環境で動作を確認。
cd /path/to/nextcloud/root/directory/core/skeleton && pwd筆者環境/home/www-data/nextcloud/core/skeleton
ここに、アカウント作成時に自動的に追加されるファイルが含まれています。
等を消していきます。
例)
sudo rm 'Reasons to use Nextcloud.pdf'任意の方法でファイル(マニュアルなど)をこのディレクトリに入れることで、アカウント作成時にそのファイルが追加されます。その場合は
sudo chown www-data hogeとして、ファイルの所有者をapache(nextcloud)の実行者に変えます。
sudo systemctl restart apache2.service && echo $?0を確認します。
systemctl status apache2.serviceactive(running)を確認します。

Redmineサーバからリマインダーのメールが送信されない事象を解決したときのメモ書きです。
サーバにはメール送信の機能を有しておらず、gmailのアプリ連携でメールを飛ばしています。
cd /path/to/redmine/root/directory && pwd筆者環境/home/www-data/redmine
sudo -u www-data bundle exec rake redmine:send_reminders days=7 RAILS_ENV=productionリマインダメール送信されず。
そこで、production.logを確認したところ、メール送信時に以下のエラーログが出力されました:
ERROR -- : [ActiveJob] [ActionMailer::MailDeliveryJob] Email delivery error: SSL_connect returned=1 errno=0 peeraddr=xxx.xxx.xxx.xxx:587 state=error: certificate verify failed (unable to get local issuer certificate)どうやら、証明書回りのエラーのようです。
まず、メール設定を再確認しました。RedmineでのSMTP設定は特に変更していないため、問題は設定に起因するものではないと判断しました。
そこで思い当たる節。
パッケージ管理システムからではなく、手動で OpenSSL を更新した影響で、証明書ストアのパスが /usr/bin/openssl から /usr/local/ssl に変更されていたことが原因だと分かりました。
/usr/local/ssl/bin/openssl version -d→ OPENSSLDIR: "/usr/local/ssl" を確認。
新しい証明書ストア /usr/local/ssl にシステムの CA 証明書をコピーしました:
sudo cp /etc/ssl/certs/ca-certificates.crt /usr/local/ssl/cert.pemまた、証明書ディレクトリを作成し、必要な証明書を全てコピーしました:
sudo mkdir -p /usr/local/ssl/certssudo cp -r /etc/ssl/certs/* /usr/local/ssl/certs/sudo /usr/local/ssl/bin/c_rehash /usr/local/ssl/certs//etc/environmentに以下の内容を追記しました。
SSL_CERT_FILE=/usr/local/ssl/cert.pem
SSL_CERT_DIR=/usr/local/ssl/certssudo source /etc/environmentsudo systemctl restart apache2.service ; echo $?0を確認
systemctl status apache2.serviceactive(running)を確認
cd /path/to/redmine/root/directory && pwd筆者環境/home/www-data/redmine
sudo -u www-data bundle exec rake redmine:send_reminders days=7 RAILS_ENV=production今度は正常に送信されることを確認しました。
Redmineからメールが送信できなかった問題は、手動で更新したOpenSSLの証明書ストアのパス設定が原因でした。
証明書ストアが適切に設定されていないと、SMTP 送信時に certificate verify failed エラーが発生。
証明書関連の問題が発生した場合、OPENSSLDIR を確認し、適切な CA 証明書が配置されているかチェックすることが重要。
また、証明書周りはシステム全体に影響を及ぼすため、確認が甘かったということも事実。これは、手動でOpenSSLをアップグレードする際にも、改めて手順を確認します。

外部に公開しているRedmineサイト。
https://plan.io/redmine-security-scanner
で確認したところ、評価はA。
X-Content-Type-Options header not set Content sniffing may enable cross-site scripting attacks. Since your Redmine server is not properly sending the X-Content-Type-Options header, your users are vulnerable to this attack vector.
の診断が出てA+に至りませんでした。
そこで、設定を修正し、脆弱性評価をA+に引き上げます。
で以下の箇所を確認。
Header always set Strict-Transport-Security "max-age=63072000"
Header set X-Content-Type-Options "nosniff"
Header always append X-Frame-Options "SAMEORIGIN"
Header set X-XSS-Protection "1; mode=block"
セキュリティヘッダーの適用方法を見直し、適切に設定されるよう修正します。
sudo cp -pi /etc/apache2/sites-available/redmine.conf /path/to/backup/directory/redmine.conf.$(date +%Y%m%d)
※自分のRedmineサイトの設定ファイルを指定します。
任意のバックアップディレクトリを指定します。(筆者環境 /etc/apache2/old/redmine.conf.$(date +%Y%m%d)
diff -u /path/to/backup/directory/redmine.conf.$(date +%Y%m%d) /etc/apache2/sites-available/redmine.conf
差分がなければ(エラーがなければ)バックアップ成功です。
上記のredmine.confを、以下の差分になるように修正します。(管理者権限が必要)
- Header set X-Content-Type-Options "nosniff"
- Header always append X-Frame-Options "SAMEORIGIN"
- Header set X-XSS-Protection "1; mode=block"
+ Header always set X-Content-Type-Options "nosniff"
+ Header always set X-Frame-Options "SAMEORIGIN"
+ Header always set X-XSS-Protection "1; mode=block"
diff -u /path/to/backup/directory/redmine.conf.$(date +%Y%m%d) /etc/apache2/sites-available/redmine.conf
上記の差分が出てくればOKです。
sudo apache2ctl configtest
→ Syntax OKを確認します。
systemctl status apache2.service
→ active (running)を確認します。
sudo systemctl restart apache2.service && echo $?
→ 成功時は 0 が出力されます。
systemctl status apache2.service
→ active (running)を確認します。
curl -I https://redmineサイト
以下のような表示を確認します。
X-Permitted-Cross-Domain-Policies: none
X-XSS-Protection: 1; mode=block
X-Request-Id: ***********
X-Download-Options: noopen
X-Frame-Options: SAMEORIGIN
X-Runtime: 0.615862
X-Content-Type-Options: nosniff
https://plan.io/redmine-security-scanner
でURLを入力します。
過去の診断結果が表示されるため、『Re-Scan』をクリックして最新の診断結果を取得します。
「A+」の評価と、以下のような表示が出れば修正できています。
It looks like you are running Redmine 5.1.4. That's a version without any known security issues. Your Redmine is protected by properly configured TLS/SSL. All security relevant headers are configured properly. It appears that you have 3 or more Redmine plugins installed.

firefly-iiiのアップグレードを試みたところ、失敗。その記録と原因についてメモを残します。
cd /hoge && pwd任意の作業ディレクトリに移動します。
mysqldump --no-tablespaces --single-transaction -u username -h localhost -p database_name > DB_Backup.$(date +%Y%m%d).sqlusename、database_name、及びDB_Backupは自分の環境に合わせます。
head -100 DB_Backup.$(date +%Y%m%d).sqlバックアップができていること、平文でSQLが読めることを確認します。
cd /hoge && pwd任意の作業ディレクトリに移動します。
wget https://github.com/firefly-iii/firefly-iii/releases/download/v6.2.5/FireflyIII-v6.2.5.zipsudo chown www-data:www-data FireflyIII-v6.2.5.zipls -l FireflyIII-v6.2.5.zipファイルがあること、所有者がWebアプリ実行ユーザ(www-data)であることを確認します。
sudo mv /home/www-data/firefly-iii /home/www-data/firefly-iii.$(date +%Y%m%d)自分の環境に合わせます。firefly-iiiがインストールされているディレクトリをまるごと移動します。
ls -ld /home/www-data/firefly-iii→ ディレクトリが無いこと
ls -ld /home/www-data/firefly-iii.$(date +%Y%m%d)→ ディレクトリがあること
sudo -u www-data unzip -o /hoge/FireflyIII-v6.2.5.zip -x "storage/*" -d /home/www-data/firefly-iii/hogeは先ほど取得したパッケージがある場所です。アップデート前と同じ位置、名前に解凍します。
ls -l /home/www-data/firefly-iiiファイル一式があり、www-dataが所有者になっていること
cd /home/www-data/firefly-iii.$(date +%Y%m%d) && pwd自分の環境に合わせます。
.envファイルをコピーsudo -u www-data cp -pi .env /home/www-data/firefly-iii/.envコピー先のディレクトリは自分の環境に合わせます。
.envファイルコピー確認ls -l /home/www-data/firefly-iii/.envファイルがあることを確認します。
sudo -u www-data cp -pir storage /home/www-data/firefly-iii/ls -l /home/www-data/firefly-iii/storageファイルやディレクトリがあることを確認します。
cd /home/www-data/firefly-iii && pwd先ほど展開したディレクトリに移動します。
sudo -u www-data php artisan migrate --seedここで失敗。以下のエラーが出ました。
Composer detected issues in your platform:
Your Composer dependencies require a PHP version ">= 8.4.0". You are running 8.3.16.
PHP Fatal error: Composer detected issues in your platform: Your Composer dependencies require a PHP version ">= 8.4.0". You are running 8.3.16. in /home/www-data/firefly-iii/vendor/composer/platform_check.php on line 22
そのため、切り戻しを行います。
cd /home/www-data && pwd自分の環境に合わせます。
sudo rm -rf /home/www-data/firefly-iiisudo mv /home/www-data/firefly-iii.$(date +%Y%m%d) /home/www-data/firefly-iiils -l /home/www-data/firefly-iiiファイル一式があり、www-dataが所有者になっていること
sudo systemctl restart apache2.servicesystemctl status apache2.serviceこれは明白にして単純です。
リリースノートを確認していなかった
に尽きます。LAMP環境で動くからこそ、ミドルウェアのバージョン(この場合はPHP)の必要とするバージョンを確認していなかった自分の落ち度です。
v6.2.0のリリースノートに
Firefly III requires PHP 8.4.
と書かれていることを見落としていました。
「切り戻しを前提としていた手順」に助けられました。
させる二段構えにより、迅速な切り戻しが可能になりました。
結局のところ、
「自分の確認不足」から来るミスを「自分の確認不足を想定した手順」でカバーした形です。

環境でNextcloudを30.xの最新版にアップデート後、以下の警告が出ました。
One or more mimetype migrations are available. Occasionally new mimetypes are added to better handle certain file types. Migrating the mimetypes take a long time on larger instances so this is not done automatically during upgrades. Use the command
occ maintenance:repair --include-expensiveto perform the migrations.現在、あなたは PHP 8.1.31 を実行しています。PHP 8.1 は Nextcloud 30 では非推奨となっています。Nextcloud 31 では少なくとも PHP 8.2 が必要になる可能性があります。できるだけ早く、PHP グループが提供する公式にサポートされている PHP のバージョンにアップグレードしてください。 詳細については、ドキュメント↗を参照してください。
いくつかの欠落しているオプションのインデックスを検出しました。データベースのパフォーマンスを向上させるために、(Nextcloudまたはインストールされたアプリケーションによって)新しいインデックスが追加されることがあります。インデックスの追加には時間がかかり、一時的にパフォーマンスが低下することがあるため、アップグレード時には自動的には行われません。インデックスが追加されると、それらのテーブルへのクエリが速くなるはずです。インデックスを追加するには、occ db:add-missing-indicesコマンドを使用してください。インデックスが不足: "fs_name_hash" テーブル内の "filecache". 詳細については、ドキュメント↗を参照してください。
これに対して対応を行います。
Webサーバの全体的な変更を伴います。作業は慎重に、可能な限り検証環境で試してからの反映を強く推奨します。
cd /path/to/nextcloud/root/directory && pwd自分の環境に合わせます。(筆者環境/home/www-data/nextcloud)
sudo -u www-data php occ maintenance:mode --on運用中のNextcloudのURLにアクセスし、メンテナンスモードであることを確認します。
cd /hoge && pwd任意のディレクトリを指定します。
mysqldump -h localhost -u nextcloud -p --no-tablespaces --single-transaction nextcloud > nextcloud_backup.$(date +%Y%m%d).sqlDB名やユーザーは自分の環境に合わせます。
ls -la nextcloud_backup.$(date +%Y%m%d).sqlファイルがあることを確認します。
sudo aptitude install php8.2→ 好みでaptitudeを用いています。aptでもOKです。
sudo aptitude install php8.2-{opcache,pdo,bcmath,calendar,ctype,fileinfo,ftp,gd,intl,json,ldap,mbstring,mysql,posix,readline,sockets,bz2,tokenizer,zip,curl,iconv,phar,xml,dev,imagick,gmp}sudo aptitude install libapache2-mod-php8.2sudo a2dismod php8.1sudo a2enmod php8.2sudo systemctl reload apache2.servicephp -v表示例PHP 8.2.27 (cli) (built: Jan 2 2025 15:36:15) (NTS)
cd /etc/php/8.2/cli/conf.dcat <<- __EOF__ | sudo tee -a /etc/php/8.2/cli/conf.d/10-opcache.ini
opcache.enable=1
opcache.enable_cli=1
opcache.interned_strings_buffer=16
opcache.max_accelerated_files=10000
opcache.memory_consumption=128
opcache.save_comments=1
opcache.revalidate_freq=1
__EOF__cat <<- __EOF__ | sudo tee -a /etc/php/8.2/cli/conf.d/20-apcu.ini
[apcu]
apc.enabled=1
apc.shm_size=32M
apc.ttl=7200
apc.enable_cli=1
apc.serializer=php
__EOF__php.iniバックアップ
sudo cp -pi /etc/php/8.2/apache2/php.ini /path/to/backup/php.ini.$(date +%Y%m%d)任意のバックアップディレクトリを指定します。(筆者環境/etc/old/)
diff -u /etc/php/8.2/apache2/php.ini /path/to/backup/php.ini.$(date +%Y%m%d)差分が存在しないことにより、バックアップが取れていることを確認します。
sudo sed -i 's/memory_limit = 128M/memory_limit = 512M/g' /etc/php/8.2/apache2/php.inimemory_limitを推奨値の512Mに置き換えます。
diff -u /path/to/backup/php.ini.$(date +%Y%m%d) /etc/php/8.2/apache2/php.ini-memory_limit = 128M
+memory_limit = 512Msudo systemctl restart apache2.servicecd /path/to/nextcloud/root/directory && pwd自分の環境に合わせます。
sudo -u www-data php8.2 occ maintenance:repair --include-expensivesudo -u www-data php8.2 occ db:add-missing-indicessudo -u www-data php8.2 occ maintenance:mode --off何か不具合があった場合の切り戻し手順です。上記、メンテナンスモードを有効化してから行ってください。
sudo a2dismod php8.2sudo a2enmod php8.1sudo systemctl restart apache2.servicephp -v→ 8.1に戻っていることを確認します。
ls -l /hoge/nextcloud_backup.$(date +%Y%m%d).sqlバックアップを行ったディレクトリを指定します。
head -100 /hoge/nextcloud_backup.$(date +%Y%m%d).sqlファイルがあること、平文で読めることを確認します。
mysql -u root -pSHOW DATABASES;nextcloudが動いているDBであることを再確認してください。
SELECT COUNT(*) FROM nextcloud.oc_users;二回ほど深呼吸して、落ち着いて作業しましょう。
DROP DATABASE nextcloud;CREATE DATABASE IF NOT EXISTS nextcloud CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;EXITmysql -h localhost -u nextcloud -p nextcloud < /hoge/nextcloud_backup.$(date +%Y%m%d).sqlこの後、メンテナンスモードを解除して、以前と同じ状態か確認します。
平文でSQLがサーバ上にあるのは危険な状態なので、以下の措置を執ります。
cd /hoge && pwdバックアップを行ったディレクトリを指定します。
ls -la nextcloud_backup.$(date +%Y%m%d).sqlファイルがあることを確認します。
shred -u nextcloud_backup.$(date +%Y%m%d).sqlls -la nextcloud_backup.$(date +%Y%m%d).sqlファイルが無いことを確認します。

Webサーバ1つに複数のサイトを運用している場合、
「バーチャルホストでどんなWebサービスが動いているか?」「設定変更後の構文は正しいか?」「Webサービス再起動後、ステータスは正常か?」
を確認したい場合は多々あります。
それを解決するためのスクリプトがこちらです。
/etc/apache2/site-enabledを踏襲apache2-check.sh#!/bin/bash
# サイト設定ディレクトリ
SITES_DIR="/etc/apache2/sites-enabled"
# スクリプトを root ユーザーで実行しているかチェック
if [ "$EUID" -ne 0 ]; then
echo "このスクリプトは root 権限で実行する必要があります。"
exit 1
fi
# 1. /etc/apache2/sites-enabled 配下のファイルとURL表示
echo "==== 有効なサイト設定ファイル ===="
if [ -z "$(ls -A "$SITES_DIR")" ]; then
echo "サイト設定が存在しません。"
else
for site in "$SITES_DIR"/*; do
echo "設定ファイル: $(basename "$site")"
# ServerNameとServerAliasを正規化して抽出
entries=$(grep -hi -E "ServerName|ServerAlias" "$site" | sed -E 's/^[[:blank:]]+//;s/[[:blank:]]*#.*//' | awk '{
original_directive = $1
directive = tolower(original_directive)
proper_directive = (directive == "servername") ? "ServerName" :
(directive == "serveralias") ? "ServerAlias" : original_directive
for (i=2; i<=NF; i++) {
domain = tolower($i)
sub(/[;,]*$/, "", domain)
gsub(/^[[:blank:]]+|[[:blank:]]+$/, "", domain)
if (domain) {
printf "%s %s\n", proper_directive, domain
}
}
}' | sort -u)
if [ -z "$entries" ]; then
echo " ※ ServerName/ServerAliasが定義されていません"
else
echo "$entries" | sed 's/^/ /'
fi
echo
done
fi
echo "=================================="
# 2. Apache構文チェック
echo "構文チェック中..."
if ! apachectl configtest; then
echo "構文エラーが検出されました。Apacheを再起動できません。"
exit 1
fi
echo "構文チェック完了: 問題ありません。"
# 3. Apache再起動の確認
read -p "Apacheを再起動しますか? (y/n): " CONFIRM
if [[ "$CONFIRM" =~ ^[Yy]$ ]]; then
echo "Apacheを再起動します..."
if ! systemctl restart apache2; then
echo "Apacheの再起動に失敗しました。"
exit 1
fi
echo "Apacheが正常に再起動されました。"
# 4. Apacheステータス確認
echo "==== Apacheステータス ===="
systemctl status apache2 --no-pager
else
echo "Apacheの再起動はキャンセルされました。"保存後、
sudo chmod +x apache2-check.shとして、
sudo bash apache2-check.shを実行することで、
を一括で行うことができます。
このスクリプトを使うことで、Apacheの設定確認と再起動作業が大幅に効率化されました。
SSL証明書の有効期限を確認するスクリプト、改修しました。
require 'openssl'
require 'socket'
require 'date'
require 'uri'
require 'timeout'
# ユーザーからURLを対話的に受け取る
def get_user_input
print "チェックしたいサイトのドメインを入力してください(例: example.com): "
domain = gets.chomp
# 入力がhttp://またはhttps://で始まらない場合は、https://を追加
domain = "https://#{domain}" unless domain.start_with?('http://', 'https://')
domain
end
# 変数で指定したURLに接続して証明書の有効期限を取得するメソッド
def get_certificate_expiry_date(url)
uri = URI.parse(url)
hostname = uri.host
ssl_socket = nil
tcp_client = nil
begin
# タイムアウトを5秒に設定してSSL接続を確立
Timeout.timeout(5) do
tcp_client = TCPSocket.new(hostname, 443)
ssl_context = OpenSSL::SSL::SSLContext.new
ssl_socket = OpenSSL::SSL::SSLSocket.new(tcp_client, ssl_context)
ssl_socket.hostname = hostname
ssl_socket.connect
# 証明書の有効期限を取得
cert = ssl_socket.peer_cert
expiration_date = DateTime.parse(cert.not_after.to_s)
days_remaining = (expiration_date - DateTime.now).to_i
return expiration_date, days_remaining
end
rescue Timeout::Error
return nil, "サーバーへの接続がタイムアウトしました。"
rescue => e
return nil, e.to_s
ensure
ssl_socket&.close
tcp_client&.close
end
end
# メイン処理
def main
# コマンドライン引数を確認
url = if ARGV[0]
# 引数でドメインが指定されている場合
domain = ARGV[0]
domain = "https://#{domain}" unless domain.start_with?('http://', 'https://')
domain
else
# 対話的に入力を受け付ける
get_user_input
end
expiration_date, days_remaining = get_certificate_expiry_date(url)
if expiration_date
formatted_date = expiration_date.strftime("%Y/%m/%d")
puts "サイト #{url} の有効期限は #{formatted_date} です。残り #{days_remaining} 日です。"
else
puts "証明書の取得に失敗しました: #{days_remaining}"
end
end
# メイン処理を呼び出し
main
引数化したことです。
ruby ssl_checker.rb google.co.jp
サイト https://google.co.jp の有効期限は 2025/03/31 です。残り 61 日です。と、スクリプトの後にドメイン指定で残り日数を示します。
ruby ssl_checker.rb
チェックしたいサイトのドメインを入力してください(例: example.com): google.co.jp
サイト https://google.co.jp の有効期限は 2025/03/31 です。残り 61 日です。引数なしだと対話式に切り替わります。
これで、変数をハードコートする必要がなくなり、他のスクリプトにも組み込みやすくなりました。
以前作成したコマンドラインでの天気予報ツールについて改良を行いました。
まず、修正前のスクリプトはこちらです。
#!/bin/bash
# 都市名をコマンドライン引数から取得するか、ユーザーに尋ねる
city=$1
if [[ -z "$city" ]]; then
echo "都市名を入力してください:"
read city
if [[ -z "$city" ]]; then
echo "都市名が入力されませんでした。"
exit 1
fi
fi
# ansiweatherコマンドを実行して天気情報を表示
echo "ansiweatherの情報:"
if ! ansiweather -l "$city"; then
echo "ansiweatherから情報を取得できませんでした。"
fi
# curlコマンドを使用してwttr.inから天気情報を表示
echo "wttr.inの情報:"
if ! curl -s "wttr.in/${city}?lang=ja"; then
echo "wttr.inから情報を取得できませんでした。"
fiこのスクリプトは、コマンドライン引数で都市名を受け取るか、引数がなければユーザーに都市名の入力を求め、ansiweatherとcurlを使って天気情報を取得し表示します。
ansiweatherやcurlコマンドが失敗した場合の処理は警告メッセージを表示するだけです。そこで、以下のように修正です。
#!/bin/bash
# 都市名を取得する関数
get_city() {
if [[ -z "$1" ]]; then
read -p "都市名を入力してください: " city
if [[ -z "$city" ]]; then
echo "エラー: 都市名が入力されていません。" >&2
return 1
fi
else
city="$1"
fi
# 入力値の検証
if [[ "$city" =~ ^[[:space:]]+$ ]]; then
echo "エラー: 都市名に空白のみが入力されています。" >&2
return 1
fi
return 0
}
# 天気情報を表示する関数
show_weather() {
local city="$1"
echo "--------------------"
echo "ansiweatherの情報 (${city}):"
if ! ansiweather -l "$city"; then
echo "警告: ansiweatherから情報を取得できませんでした。" >&2
fi
echo "--------------------"
echo "wttr.inの情報 (${city}):"
if ! curl -fs --connect-timeout 5 "wttr.in/${city}?lang=ja"; then
echo "警告: wttr.inから情報を取得できませんでした。" >&2
fi
}
# メイン処理
if [[ $# -eq 0 ]]; then
if ! get_city; then
exit 1
fi
show_weather "$city"
elif [[ $# -gt 0 ]]; then
for city in "$@"; do
if ! get_city "$city"; then
echo "$city の処理をスキップします。" >&2
continue
fi
show_weather "$city"
done
fi
exit 0get_city()関数とshow_weather()関数に処理を分割し、コードの可読性と再利用性を向上させました。get_city()関数内で都市名が入力されない場合や空白のみが入力された場合にエラーメッセージを出力し、終了ステータスを返しています。エラーメッセージは標準エラー出力(>&2)に出力することで、通常の出力と区別しています。show_weather()関数内でansiweatherやcurlコマンドが失敗した場合に警告メッセージを標準エラー出力に出力するように変更しました。get_city()関数内で空白のみの入力に対する検証を追加しました。forループを使って、それぞれの都市に対して天気情報を取得し表示します。./script Narita Londonとすることで、出発地と目的地の天気を同時に示すことができます。curlコマンドのオプション変更: curl -sに加えて-f(エラー時にHTTPステータスコードを返す)と--connect-timeout 5(接続タイムアウトを5秒に設定)を追加し、より堅牢な処理を実現しました。./script.sh Osaka Kyotoansiweatherやcurlコマンドが失敗した場合、警告メッセージが標準エラー出力に出力されるようになりました。curlコマンドのタイムアウトが設定されたため、ネットワークの問題などで応答がない場合に処理が止まるのを防ぐことができます。Powered by WordPress & Theme by Anders Norén